
Classroom activities to discuss machine learning accuracy and ethics | Hello World #18
In Hello World issue 18, available as a free PDF download, teacher Michael Jones shares how to use Teachable Machine with learners aged 13–14 in your classroom to investigate issues of accuracy and ethics in machine learning models.


Machine learning: Accuracy and ethics
The landscape for working with machine learning/AI/deep learning has grown considerably over the last couple of years. Students are now able to develop their understanding from the hard-coded end via resources such as Machine Learning for Kids, get their hands dirty using relatively inexpensive hardware such as the Nvidia Jetson Nano, and build a classification machine using the Google-driven Teachable Machine resources. I have used all three of the above with my students, and this article focuses on Teachable Machine.
For this module, I’m more concerned with the fuzzy end of AI, including how credible AI decisions are, and the elephant-in-the-room aspect of bias and potential for harm.
Michael Jones
For the worried, there is absolutely no coding involved in this resource; the ‘machine’ behind the portal does the hard work for you. For my Year 9 classes (students aged 13 to 14) undertaking a short, three-week module, this was ideal. The coding is important, but was not my focus. For this module, I’m more concerned with the fuzzy end of AI, including how credible AI decisions are, and the elephant-in-the-room aspect of bias and potential for harm.
Getting started with Teachable Machine activities
There are three possible routes to use in Teachable Machine, and my focus is the ‘Image Project’, and within this, the ‘Standard image model’. From there, you are presented with a basic training scenario template — see Hello World issue 16 (pages 84–86) for a step-by-step set-up and training guide. For this part of the project, my students trained the machine to recognise different breeds of dog, with border collie, labrador, saluki, and so on as classes. Any AI system devoted to recognition requires a substantial set of training data. Fortunately, there are a number of freely available data sets online (for example, download a folder of dog photos separated by breed by accessing helloworld.cc/dogdata). Be warned, these can be large, consisting of thousands of images. If you have more time, you may want to set students off to collect data to upload using a camera (just be aware that this can present safeguarding considerations). This is a key learning point with your students and an opportunity to discuss the time it takes to gather such data, and variations in the data (for example, images of dogs from the front, side, or top).

Once you have downloaded your folders, upload the images to your Teachable Machine project. It is unlikely that you will be able to upload a whole subfolder at once — my students have found that the optimum number of images seems to be twelve. Remember to build this time for downloading and uploading into your lesson plan. This is a good opportunity to discuss the need for balance in the training data. Ask questions such as, “How likely would the model be to identify a saluki if the training set contained 10 salukis and 30 of the other dogs?” This is a left-field way of dropping the idea of bias into the exploration of AI — more on that later!
Accuracy issues in machine learning models
If you have got this far, the heavy lifting is complete and Google’s training engine will now do the work for you. Once you have set your model on its training, leave the system to complete its work — it takes seconds, even on large sets of data. Once it’s done, you should be ready to test you model. If all has gone well and a webcam is attached to your computer, the Output window will give a prediction of what is being viewed. Again, the article in Hello World issue 16 takes you through the exact steps of this process. Make sure you have several images ready to test. See Figure 1a for the response to an image of a saluki presented to the model. As you might expect, it is showing as a 100 percent prediction.
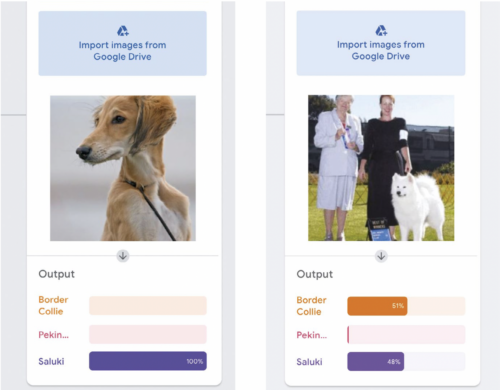
It will spark an interesting discussion if you now try the same operation with an image with items other than the one you’re testing in it. For example see Figure 1b, in which two people are in the image along with the Samoyed dog. The model is undecided, as the people are affecting the outcome. This raises the question of accuracy. Which features are being used to identify the dogs as border collie and saluki? Why are the humans in the image throwing the model off the scent?
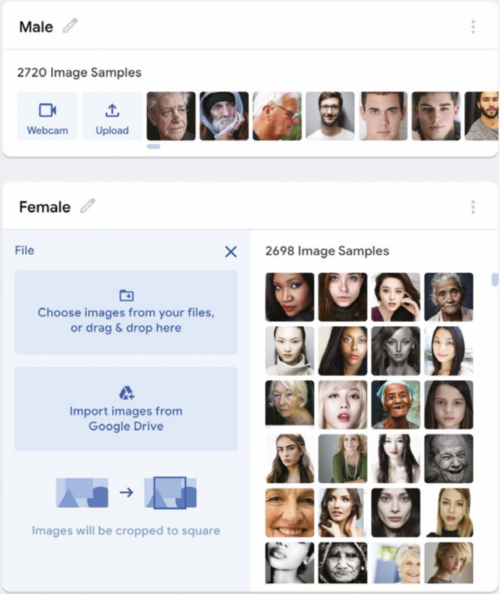
Getting closer to home, training a model on human faces provides an opportunity to explore AI accuracy through the question of what might differentiate a female from a male face. You can find a model at helloworld.cc/maleorfemale that contains 5418 images almost evenly spread across male and female faces (see Figure 2). Note that this model will take a little longer to train.
Once trained, try the model out. Props really help — a top hat, wig, and beard give the model a testing time (pun intended). In this test (see Figure 3), I presented myself to the model face-on and, unsurprisingly, I came out as 100 percent male. However, adding a judge’s wig forces the model into a rethink, and a beard produces a variety of results, but leaves the model unsure. It might be reasonable to assume that our model uses hair length as a strong feature. Adding a top hat to the ensemble brings the model back to a 100 percent prediction that the image is of a male.
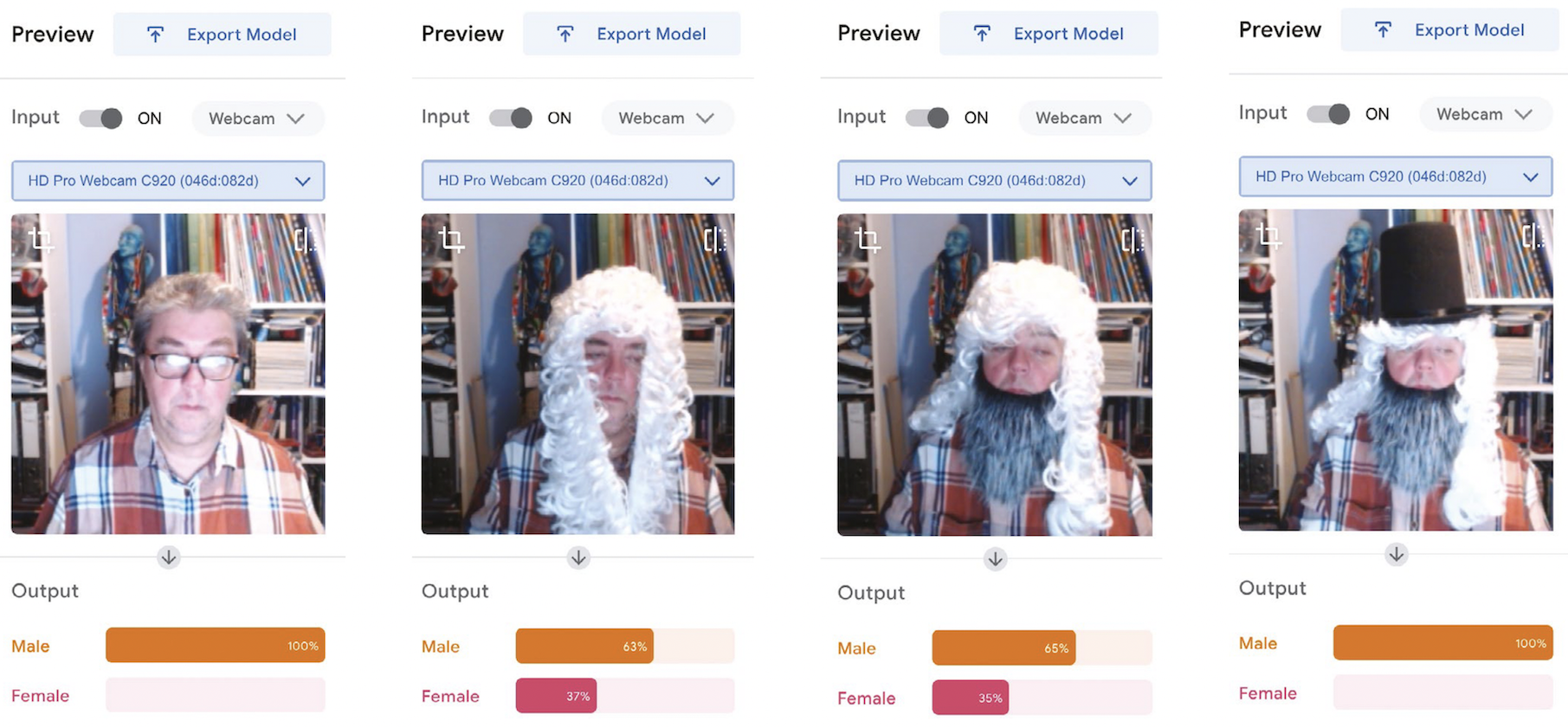
Machine learning uses a best-fit principle. The outputs, in this case whether I am male or female, have a greater certainty of male (65 percent) versus a lesser certainty of female (35 percent) if I wear a beard (Figure 3, second image from the right). Remove the beard and the likelihood of me being female increases by 2 percent (Figure 3, second image from the left).
Bias in machine learning models
Within a fairly small set of parameters, most human faces are similar. However, when you start digging, the research points to there being bias in AI (whether this is conscious or unconscious is a debate for another day!). You can exemplify this by firstly creating classes with labels such as ‘young smart’, ‘old smart’, ‘young not smart’, and ‘old not smart’. Select images that you think would fit the classes, and train them in Teachable Machine. You can then test the model by asking your students to find images they think fit each category. Run them against the model and ask students to debate whether the AI is acting fairly, and if not, why they think that is. Who is training these models? What images are they receiving? Similarly, you could create classes of images of known past criminals and heroes. Train the model before putting yourself in front of it. How far up the percentage scale are you towards being a criminal? It soon becomes frighteningly worrying that unless you are white and seemingly middle class, AI may prove problematic to you, from decisions on financial products such as mortgages through to mistaken arrest and identification.
It soon becomes frighteningly worrying that unless you are white and seemingly middle class, AI may prove problematic to you, from decisions on financial products such as mortgages through to mistaken arrest and identification.
Michael Jones
Encourage your students to discuss how they could influence this issue of race, class, and gender bias — for example, what rules would they use for identifying suitable images for a data set? There are some interesting articles on this issue that you can share with your students at helloworld.cc/aibias1 and helloworld.cc/aibias2.
Where next with your learners?
In the classroom, you could then follow the route of building models that identify letters for words, for example. One of my students built a model that could identify a range of spoons and forks. You may notice that Teachable Machine can also be run on Arduino boards, which adds an extra dimension. Why not get your students to create their own AI assistant that responds to commands? The possibilities are there to be explored. If you’re using webcams to collect photos yourself, why not create a system that will identify students? If you are lucky enough to have a set of identical twins in your class, that adds just a little more flavour! Teachable Machine offers a hands-on way to demonstrate the issues of AI accuracy and bias, and gives students a healthy opportunity for debate.
Michael Jones is director of Computer Science at Northfleet Technology College in the UK. He is a Specialist Leader of Education and a CS Champion for the National Centre for Computing Education.
More resources for AI and data science education
At the Foundation, AI education is one of our focus areas. Here is how we are supporting you and your learners in this area already:
- Hello World issue 12 focuses on AI and machine learning education, with many practical resources, insightful interviews, and inspiring features from computer science educators. Download your free copy of issue 12 now.
- In Hello World issue 16, the focus is on all things data science and data literacy for your learners. As always, you can download a free copy of the issue.
- On our Hello World podcast, we’ve got episodes where we talk with practicing computing educators about how they bring AI, AI ethics, machine learning, and data science to the young people they teach.
- Since we upgraded the Raspberry Pi–based hardware on board the International Space Station for the European Astro Pi Challenge, young people have better opportunities to use machine learning as part of the scientific experiments they write Python programs for during the Challenge. See what this teams taking part in this round of Astro Pi achieved and how you can get involved in mentoring students at your school to take part in the next round starting in September.
- If you’d like a practical introduction to the basics of machine learning and how to use it, take our free online course.

- Computing education researchers are working to answer the many open questions about what good AI and data science education looks like for young people. To learn more, you can watch the recordings from our research seminar series focused on this. We ourselves are working on research projects in this area and will share the results freely with the computing education community.
- You can find a list of free educational resources about these topics that we’ve collated based on our research seminars, seminar participants’ recommendations, and our own work.






No comments