
Bringing data science to life for K–12 students with the ‘API Can Code’ curriculum
As data and data-driven technologies become a bigger part of everyday life, it’s more important than ever to make sure that young people are given the chance to learn data science concepts and skills.


In our April research seminar, David Weintrop, Rotem Israel-Fishelson, and Peter Moon from the University of Maryland introduced API Can Code, a data science curriculum designed with high school students for high school students. Their talk explored how their innovative work uses real-world data and students’ own experiences and interests to create meaningful, authentic learning experiences in data science.
Quick note for educators: Are you interested in joining our free, exploratory data science education workshop for teachers on 10 July 2025 in Cambridge, UK? Then find out the details here.
David started by explaining the motivation behind the API Can Code project. The team’s goal was not to turn students into future data scientists, but to offer students the data literacy they need to explore and critically engage with a data-driven world.
The work was also guided by a shared view among leading teachers’ organisations that data science should be taught across all subjects in the K–12 curriculum. It also draws on strong research showing that when educational experiences connect with students’ own lives and interests, it leads to deeper engagement and better learning outcomes.
Reviewing the landscape
To prepare for the design of the curriculum, David, Rotem, and Peter wanted to understand what data science education options already exist for K–12 students. Rotem described how they compared four major K–12 data science curricula and examined different aspects, such as the topics they covered and the datasets they used. Their findings showed that many datasets were quite small in size, and that the datasets used were not always about topics that students were interested in.

The team also looked at 30 data science tools used across different K–12 platforms and analysed what each could do. They found that tools varied in how effective they were and that many lacked accessibility features to support students with diverse learning needs.
This analysis helped to refine the team’s objective: to create a data science curriculum that students find interesting and that is informed by their values and voices.
Participatory design
To work towards this goal, the team used a methodology called participatory design. This is an approach that actively involves the end users — in this case, high school students — in the design process. During several in-person sessions with 28 students aged 15 to 18 years old, the researchers facilitated low-tech, hands-on activities exploring the students’ identities and interests and how they think about data.
One activity, Empathy Map, involved students working together to create a persona representing a student in their school. They were asked to describe the persona’s daily life, interests, and concerns about technology and data:
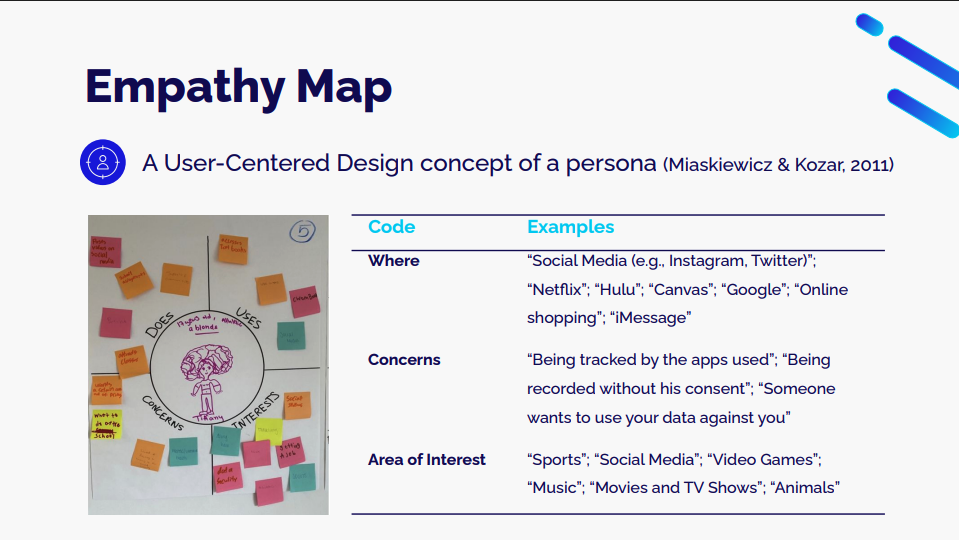
The students’ involvement in the design process gave the team a better understanding of young people’s views and interests, which helped create the design of the API Can Code curriculum.
API Can Code: three units, three key tools
Peter provided an overview of the API Can Code curriculum. It follows a three-unit flow covering different concepts and tools in each unit:
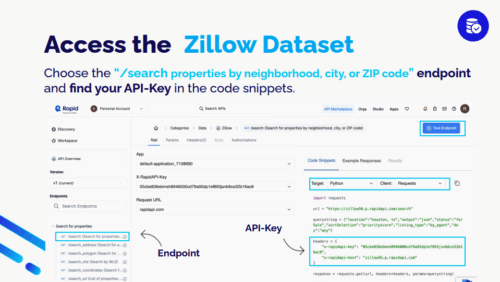
- Unit 1 introduces students to different types of data and data science terminology. The unit explores the role of data in the students’ daily lives, how use and misuse of data can affect them, different ways of collecting and presenting data, and how to evaluate databases for aspects such as size, recency, and trustworthiness. It also introduces them to RapidAPI, a hub that connects to a wide range of APIs from different providers, allowing students to access real-world data such as Zillow housing prices or Spotify music data.
- Unit 2 covers the computing skills used in data science, including the use of programming tools to run efficient data science techniques. Students learn to use EduBlocks, a block-based programming environment where students can draw in JSON files from RapidAPI datasets, and process and filter data without needing a lot of text-based programming skills. The students also compare this approach with manual data processing, which they discover is very slow.
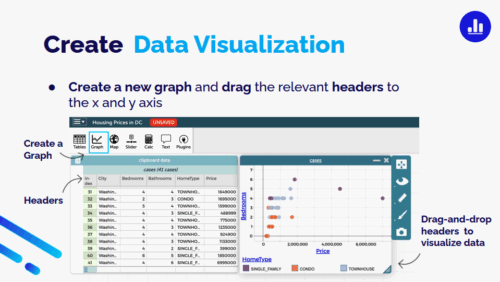
- Unit 3 focuses on data analysis, visualisation, and interpretation. Students use CODAP, a web-based interactive data science tool, to calculate summary statistics, create graphs, and perform analyses. CODAP is a user-friendly but powerful platform, making it perfect for students to analyse and visualise their data sets. Students also practise interpreting pre-made graphs and the graphs and statistics that they are creating.
Peter described an example activity carried out by the students, showing how these three units flow together and build both technical skills and an understanding of the real-world uses of data science. Students were tasked with analysing a dataset from Zillow, a property website, to explore the question “How much does a house in my neighbourhood cost?” The images below show the process the students followed, which uses the data science skills and tools from all three units of the curriculum.

Interest-driven learning in action
A central tenet of API Can Code is that students should explore data that matters to them. A diverse range of student interests was identified during the design work, and the curriculum uses these areas of interest, such as music, movies, sports, and animals, throughout the lessons.
The curriculum also features an open-ended final project, where students can choose a research question that is important to them and their lives, and answer it using data science skills.
The team shared two examples of memorable final projects. In one, a student set out to answer the question “Is Jhené Aiko a star?” The student found a publicly available dataset through an API provided by Deezer, a music streaming platform. She wrote a program that retrieved data on the artist’s longevity and collaborations, analysed the data, and concluded that Aiko is indeed a star. What stood out about this project wasn’t just the fact that the student independently defined stardom and answered their research question using real data, but that this was a truly personal, interest-driven project. David noted that the researchers could never have come up with this activity, since they had never previously heard of Jhené Aiko!

(Photo by Charito Yap, licensed under CC BY-ND 2.0)
Another student’s project analysed data about housing in Washington DC to answer the question “Which ward in DC has the most affordable houses?” Rotem explained that this student was motivated by her family thinking about moving away from the city. She wanted to use her project to persuade her parents to stay by identifying the most affordable ward in DC that they could move to. She was excited by the outcome of her project, and she presented her findings to other students and her parents.
These projects underscore the power of personally important data science projects driven by students’ interests. When students care about the questions they are exploring, they’re more invested in the process and more likely to keep using the skills and concepts they learn.
Resources
API Can Code is available online and completely free to use. Teachers can access lesson plans, tutorial videos, assessment rubrics, and more from the curriculum’s website https://apicancode.umd.edu/. The site also provides resources to support students, including example programs and glossaries.
Join our next seminar
In our current seminar series, we’re exploring teaching about AI and data science. Join us at our next seminar on Tuesday, 17 June from 17:00 to 18:30 BST to hear Netta Iivari (University of Oulu) introduce transformative agency and its importance for children’s computing education in the age of AI.
To sign up and take part in our research seminars, click below:
You can also view the schedule of our upcoming seminars, and catch up on past seminars on our previous seminars and recordings page.






2 comments
Simon Hahn
This curriculum sounds fantastic! It’s great to see data science being integrated into K-12 education. Looking forward to seeing how it evolves and impacts students!
Raspberry Pi Staff Diana Kirby — post author
Thanks for taking the time to comment, Simon! I’m glad you found the post interesting. Totally agree that API Can Code is such a great example of how to introduce data science to K-12 students. There’s lots of work happening in this space at the moment and it’s brilliant to see!