
AI is not neutral: What recent research says about bias, identity, and power
Artificial intelligence (AI) systems are often presented as objective. But plenty of evidence shows that AI systems can reflect and reinforce existing inequalities, from healthcare and education to scientific research itself.
In the first seminar of our new research seminar series on applied AI, Thema Monroe-White from George Mason University explored how we can better understand — and challenge — these patterns. Her talk focused on race-conscious algorithmic approaches to AI and data, and what they reveal about how knowledge is produced, represented, and used.

Drawing on two large-scale studies in her seminar, Thema showed that both scientific research and AI systems are shaped by human identities and social structures, and that recognising this is essential for educators, researchers, and anyone working with data.
Who produces knowledge — and why that matters
A key idea running through Thema’s seminar was that data and algorithms are not neutral. They are shaped by the people, institutions, and systems that produce them.
Thema uses critical quantitative and intersectional approaches in her work to:
- Challenge the misconception that computational methods are objective
- Highlight how race and gender shape data and outputs
- Examine how systems of power influence what gets measured, valued, and reproduced
Thema and her collaborators have been conducting research in this area for more than a decade, developing techniques that systematically measure bias and its impact on society.
In a groundbreaking study published in 2022, just before the release of ChatGPT, Thema’s team used large-scale computational analysis of more than 5 million research articles to explore inequalities in scientific publishing. The data analysis approaches developed for this study were later used to explore bias in large language models (LLMs).
However, the 2022 study already demonstrated wide-reaching disparities in science and surfaced deep-rooted issues, showing that bias was already ingrained in the scientific data that was used to train LLM, and affecting topic choices, citation and institutional differences.
Identity and topic choice
The results showed clear inequalities in the relationship between identity and topic choice. Authors from marginalised groups were more likely to study topics related to their communities and lived realities, including topics such as racial disparities and discrimination. Gendered patterns also appeared, with women publishing more frequently on more feminised topics, including families, literacy, learning, nursing, and pregnancy.
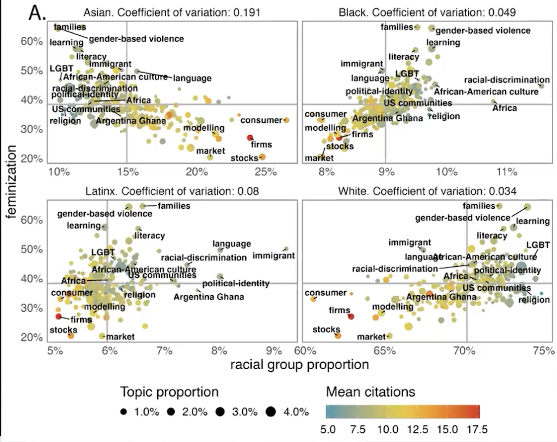
Citation inequalities
The study also found citation inequalities. Even among authors studying the same topic, authors from some groups were cited less often than others, with black and Latinx women the least likely to be cited. This shows that inequality is not only present in what gets studied, but also in whose work is recognised.
Institutional context
Institutional context mattered too. Researchers at mission-driven institutions were more likely to publish on topics connected to marginalised communities, while scholars at institutions seen as elite were more likely to publish on topics that aligned more closely with dominant groups and norms.
Taken together, the findings point to a simple but important idea: who we are shapes what knowledge gets produced. That matters because when some groups are underrepresented in research, the topics that affect their lives may also be understudied.
What AI-generated stories reveal about bias
Having already developed their tool for name analysis for the previous study, Thema’s team was uniquely positioned to analyse the bias embedded in generative AI systems, specifically LLMs.
Thema’s most recent study examined how LLM–based tools represent people in everyday scenarios. The research team prompted the base models of LLM chatbots (such as Open AI’s ChatGPT, Anthropic’s Claude, Meta’s Llama, and Google’s PaLM or Gemini) to write short stories about students, workers, and relationships, generating 500,000 outputs across different domains. They then analysed how names associated with different racial and gender identities were portrayed.

One example Thema shared in the seminar described a student named “John” helping “Maria,” a student who had moved from Mexico and was struggling with Spanish. At first glance, this may seem like a small or even odd detail. But when oddities like this appear again and again across thousands of stories, they reveal systematic patterns.
The study found that characters with marginalised identities were more likely to be portrayed in subordinated roles in chatbot outputs. Characters with non-white-associated names were more often shown as needing help rather than offering it. Stereotypes were also reinforced, with some names repeatedly associated with struggling students, subordinate workers, or narrow professional roles. Some groups were omitted altogether, while white-associated names appeared more frequently and in more powerful positions.

Similar biases appeared across stories related to education, work, and relationships. Across all three topics, the most common pattern was one in which white characters were more likely to lead, rescue, or mentor, while non-white characters were more likely to be helped, corrected, or spoken for.
For educators, this is especially important because many AI tools are now being introduced into classroom settings as writing assistants, tutors, or sources of personalised feedback. When these tools reproduce biases and unequal assumptions, they can shape not only what students read, but also how students see themselves and one another.
Towards more responsible AI tools and data practices
Rather than rejecting computational methods altogether, Thema argued for using them more thoughtfully and responsibly.
One approach she highlighted is the Wells-Du Bois protocol, a framework designed to support bias mitigation, transparency, and more reflective use of data and models. It encourages researchers and practitioners to think carefully about inadequate or biased data, identity proxies, subpopulation differences, and the kinds of harms that can arise when AI systems are used without sufficient context.
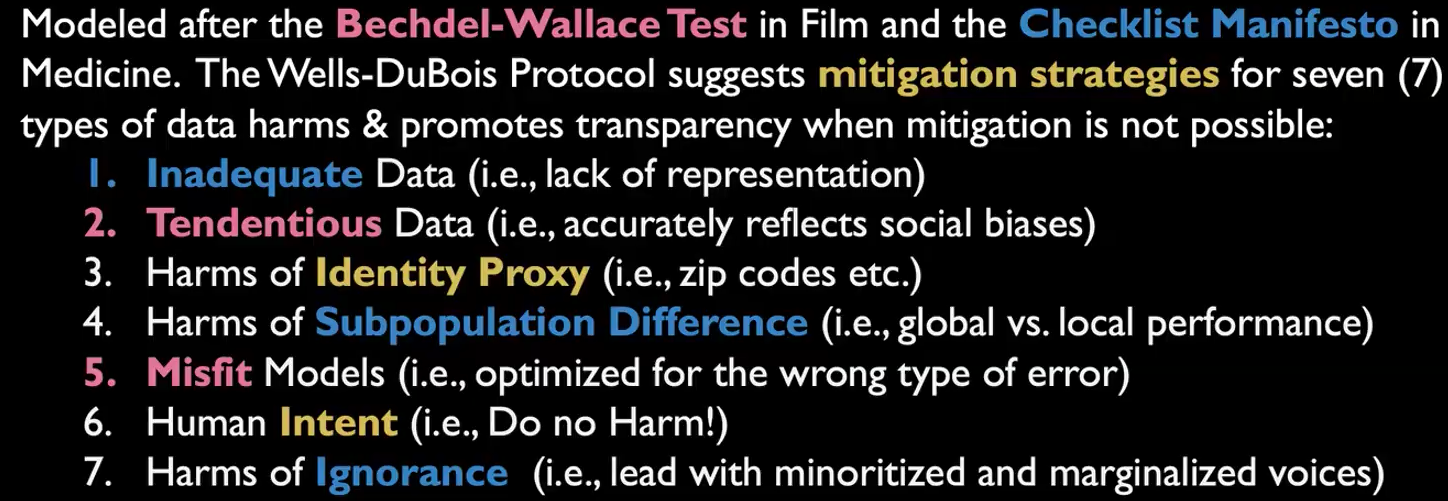
Underlying this is a broader principle: when we do not know enough, we should say so. And when systems affect marginalised communities, those communities should not be an afterthought in how we build, evaluate, or use technology.
What this means for your classroom
In her seminar, Thema emphasised the importance of thinking about how we respond to bias in AI tools in educational settings. Here are some starting points for meaningful discussions in your classroom:
- A good starting point is student agency. If AI tools are becoming part of students’ learning environments, then young people need opportunities to make informed choices about when and how to engage with them. That means not treating AI tool use as inevitable, and not assuming every student should want to use the tools in the same way. In some cases, empowering students may also mean making it clear that they can opt out.
- This also means helping learners ask better questions about the tools themselves. What leads to the kinds of bias we saw in these studies? What data were these systems trained on? Whose language, identities, and experiences are overrepresented, and whose are missing? Do the tools have access to student or classroom data, and if so, what are the implications?
- The seminar also points to the importance of resisting AI hype. In a rapidly changing landscape, it can be tempting to focus only on novelty, efficiency, or personalisation. But educators may want to take a longer-term view about AI technology use. What kinds of habits, dependencies, and expectations are these tools creating? Are they shifting students’ ideas about intelligence, creativity, or authority? What happens when biased outputs are repeated often enough to feel normal?
- Finally, the discussion around responsible use should include the wider costs of AI. Informing students about these tools should include not just potential benefits and risks, but also issues such as environmental impact and data use. A more balanced conversation can help prevent classroom discussions from reinforcing the hype that often surrounds AI.
If you would like to find out more about Thema’s work, watch the seminar recording:
You may also want to explore:
- Thema’s paper on intersectional inequalities in science
- Her work on intersectional biases in narratives produced by AI models
- The Wells-Du Bois protocol for more responsible data practice
Join our next seminar
Our research seminars bring together educators and researchers to explore key questions in computing education.
Next in our series on applied AI, our Director of Research and Impact, Shuchi Grover, will talk about the role of K–12 education in developing competencies for the future of data and computing. Sign up now to join the seminar on 12 May, 17:00 BST:






1 comment
Jump to the comment form
Geoffrey Bot
Reading this, I realize the main point isn’t just that “AI can be biased,” but that bias is built into the whole system—from the data we collect to the power structures deciding what gets prioritized. I like how it challenges the idea that AI is neutral, showing that things like identity, history, and inequality can quietly shape how AI sees and treats the world. It makes me think more critically about AI as something influenced by humans and society, not something separate from it.